TLDR: While learning about transformers, I built with Claude a first-principles interactive tutorial that I think can be helpful to others. Link: https://aabdelfattah.github.io/neural-first-principle/
In the last few weeks, I went through an interesting learning journey, diving into the transformer architecture. I know it is becoming too boring, everyone is writing about AI here, AI there, but I was always curious since the early emergence of ChatGPT to understand how those simple probabilistic neural networks that I studied in Uni could be capable of producing such coherent sentences.
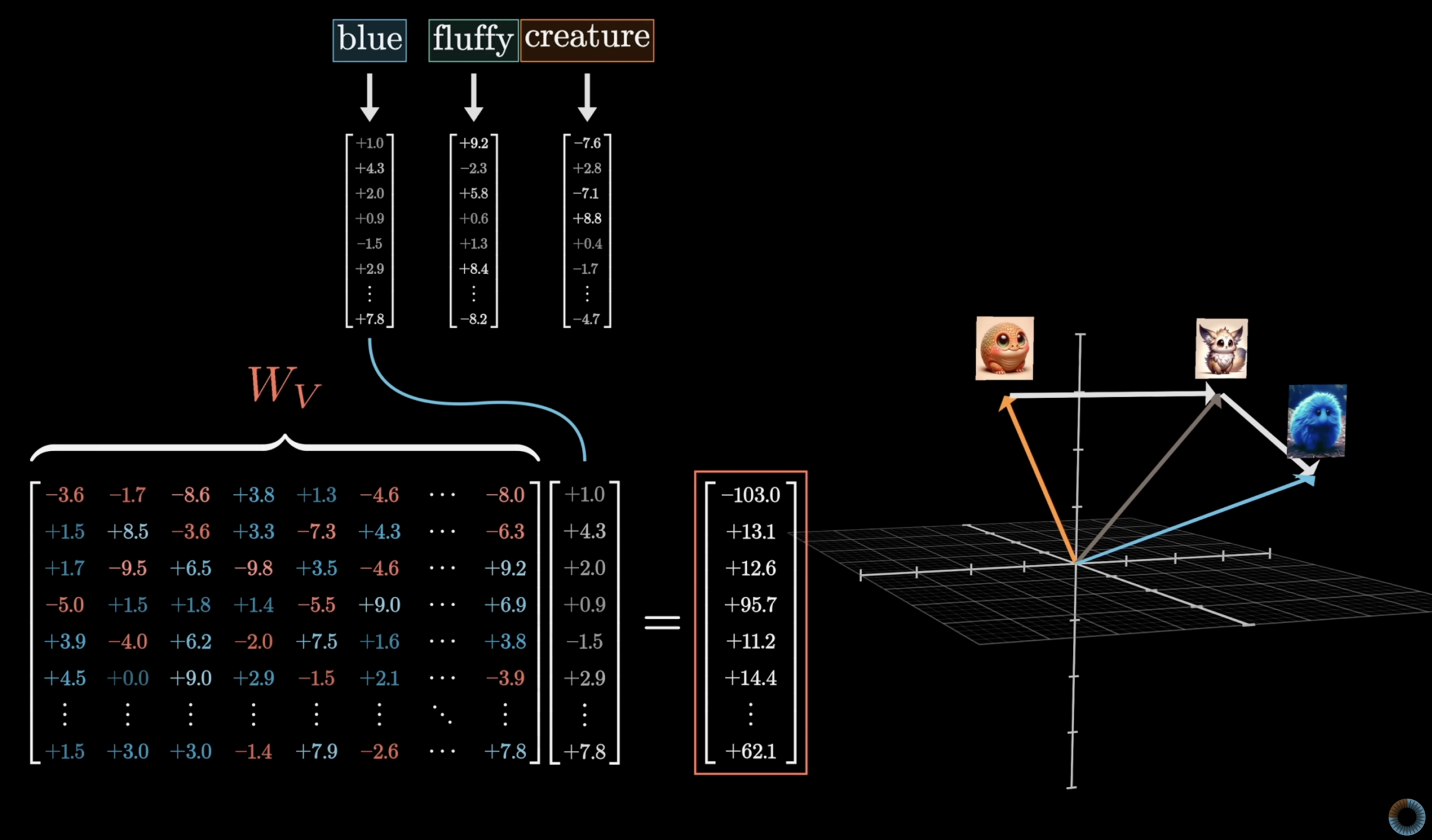
I like the first-principles learning approach, as I was learning with Claude and through different sources like Andrej Karpathy’s Deep Dive into LLMs and 3Blue1Brown’s intuitive attention explanation I built up an interactive tutorial for my own use that I found useful to share with a larger audience (side note: It is quite astnoishing to me how those guys can explain in such breadth and depth at the same time, absloute legends). I worked through the progression from simple linear regression to the complex transformer architecture, building bridges in between and connecting the dots.
Who is it for?
The tutorial is intended for anyone a bit curious and has some level of Math knowledge (not quite necessary though). I tried to keep it high-level, trying to capture the intuition but with a good level of details to reward the readers who do a second pass.
How to read it?
Start with the introduction first, and try to grasp the meaning. Through the chapters, it is supposed to be a consistent story. Then, please try the interactive visuals, and afterwards, read the details.
Too long introduction; let’s get to the tutorial:
Click through the seven stages above — or open the full tutorial in a new tab.