Are you trying to download multiple files from a webpage and bored from clicking and clicking ??
I needed to download like a 100 PDF from a single web page , so I started to look for a bash script that automates the process and found this interesting article by Guillermo Garron that combines several useful programs into a nice script to download all links from a page using lynx command line web browser and wget downloader.
First , install the the browser
$ sudo apt-get install lynx
Lynx has a nice feature that allows you to grab all links from a page
$ lynx --dump http://mlg.eng.cam.ac.uk/pub/ >> ~/links.txt
The output will be like this

So we need to filter out the first numbering column and all non pdf links for the output to be nice and readable by wget
$ lynx --dump //http://mlg.eng.cam.ac.uk/pub/ | awk '/http/{print $2}' | grep pdf >> ~/links.txt
Resulting in a clean input to wget
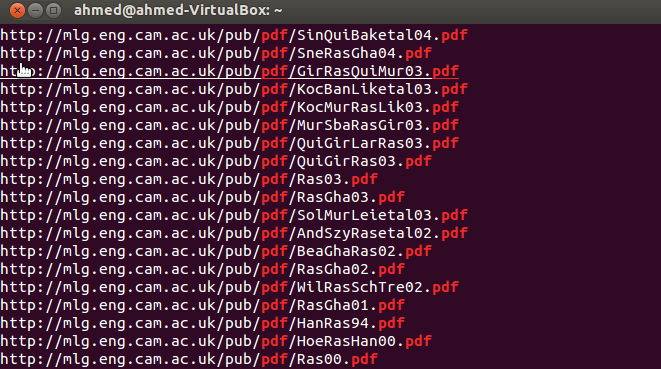
and the last step is to pass this file into wget to download all the pdfs
$ for i in $( cat ~/links.txt ); do wget $i; done
voilà ! you get all the files downloaded
Leave a Reply